在上一篇文章中,我們剖析了 A100 與 H100 這兩款算力猛獸。現在,硬體已經就緒,系統冷卻正常。是時候讓這頭猛獸開始工作了。
通用的大型語言模型(LLM)雖然強大,但它們就像一個「博學但失憶」的專家——它們看過互聯網上的所有公開資訊,卻唯獨沒看過您公司的內部機密文件、昨天的財務報告或上週的研發專利。
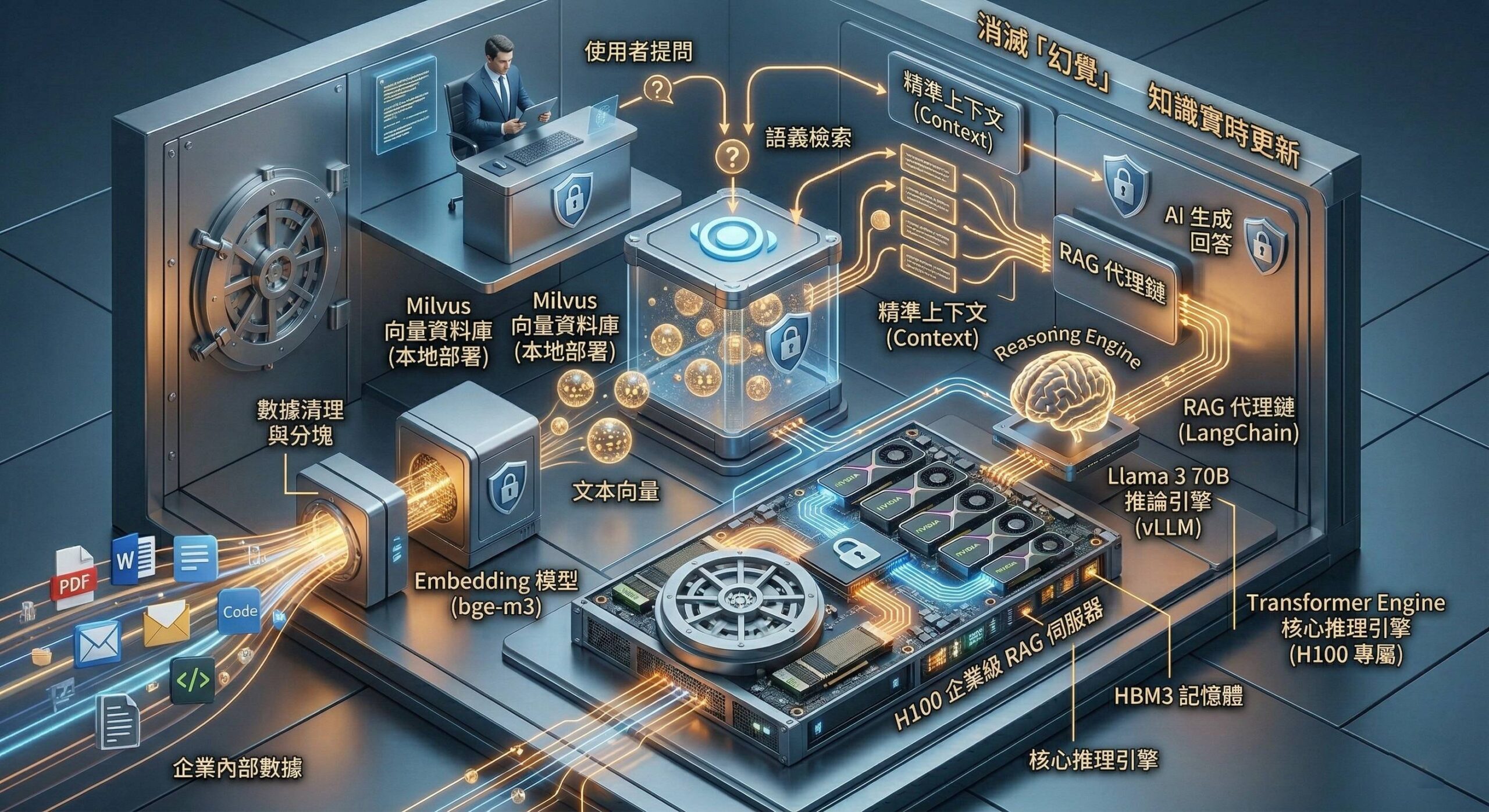
要解決這個問題,我們不能單靠微調(Fine-tuning,成本高且更新慢),而是要使用目前企業級部署最流行的架構:RAG(Retrieval-Augmented Generation,檢索增強生成)。
這篇文章將是一份硬核的實戰指南,教您如何在本地安全環境下,利用強大的 H100 算力,搭建一個真正懂您公司的 RAG 知識庫系統。
什麼是 RAG?為什麼它適合企業本地部署?
簡單來說,RAG 是一個**「開卷考試」**的過程。
- 檢索(Retrieval):當使用者提問時,系統先不急著回答,而是先從公司內部的知識庫(PDF, Word, Wiki)中,檢索出與問題最相關的幾段資訊。
- 增強(Augmented):將這些檢索到的**「精準上下文(Context)」**連同使用者的問題,一起重新組合成一個新的提示詞(Prompt)。
- 生成(Generation):將這個內容豐富的提示詞交給本地的 LLM(如 Llama 3 70B),讓它基於這些精準資訊生成回答。
RAG 的三大核心優勢(在本地環境):
- 數據主權(Data Sovereignty):所有文件、向量資料庫和模型推論都在本地,確保敏感資料絕對不外洩。
- 消滅「幻覺」(Hallucination):模型被限制只能基於檢索到的證據回答,大大提升回答的準確性。
- 知識實時更新:只需將新文件加入知識庫,無需重新訓練模型,AI 就能立刻掌握新知識。
實戰起步:RAG 軟體棧(Software Stack)選型
要在 H100 上跑 RAG,我們需要構建一套完整的軟體生態:
- 基座模型 (Base LLM):Llama 3 70B (量化版 INT4/INT8) 或 Mistral-NeMo 12B。
- 推論引擎 (Inference Engine):vLLM(目前 H100 上效能最強的框架,支持高併發)或 TensorRT-LLM。
- 向量數據庫 (Vector Database):Milvus 或 ChromaDB(本地部署首選)。
- RAG 框架 (RAG Framework):LangChain 或 LlamaIndex(用於編排整個流程)。
- Embedding 模型:專門用於將文本轉為向量的模型(如 bge-m3 或 m3e-base)。
手把手教你搭建步驟
步驟一:構建向量知識庫 (Ingestion Pipeline)
這個步驟是把公司的非結構化數據轉化為 AI 可讀的格式。
- 文件載入 (Document Loading):使用 LlamaIndex 的
SimpleDirectoryReader載入 PDF、Word、Markdown 文件。 - 文本分塊 (Text Splitting):文件太長,模型吞不下。需要將文件切分成固定大小的段落(例如每段 512 Tokens),並保持一定的重疊度(Overlap)。
- Embedding (向量化):呼叫本地的 Embedding 模型,將每個文本塊轉化為一個高維向量(例如 768 維的數字向量)。
- 存入資料庫:將這些向量連同原文(Metadata)一起存入本地的向量資料庫(如 Milvus)。
Python
# LlamaIndex 虛擬代碼範例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# 1. 載入本地文件
documents = SimpleDirectoryReader("./company_data").load_data()
# 2. & 3. 文本分塊與向量化 (底層自動呼叫 Embedding 模型)
index = VectorStoreIndex.from_documents(documents)
# 4. 存入本地持久化存儲
index.storage_context.persist(persist_dir="./storage")
步驟二:部署本地推論引擎 (LLM Serving)
這是釋放 H100 算力的關鍵。我們使用 vLLM 來部署 Llama 3 70B。
- 安裝 vLLM:確保您的環境已安裝 CUDA。
- 啟動服務:這會啟動一個與 OpenAI 相容的 API 服務。
Bash
# 在 H100 上啟動 vLLM 服務 (部署 Llama 3 70B 量化版)
python3 -m vllm.entrypoints.openai.api_server \
--model /path/to/Llama-3-70B-Instruct-GPTQ-INT4 \
--quantization gptq \
--dtype float16 \
--host 0.0.0.0 --port 8000
步驟三:編排 RAG 查詢流程 (Query Pipeline)
最後,利用 LangChain 將所有模組串聯起來。
Python
# LangChain 虛擬代碼範例
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Milvus
# 1. 連接本地運行的 LLM (vLLM API)
llm = ChatOpenAI(
model="Llama-3-70B-Instruct",
openai_api_key="EMPTY",
openai_api_base="http://localhost:8000/v1"
)
# 2. 連接本地向量資料庫
vector_store = Milvus(embedding_function=local_embedding_model, connection_args={"host": "127.0.0.1", "port": "19530"})
retriever = vector_store.as_retriever(search_kwargs={"k": 5}) # 檢索最相關的 5 段資訊
# 3. 建立 RetrievalQA 鏈
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
# 4. 提問
response = qa_chain.run("上週研發部門對專利 A 的審查意見是什麼?")
print(response)
在 H100 上進行優化的關鍵考量
既然您擁有 H100,我們不能僅僅讓它運行,而是要讓它飛起來:
- 充分利用 HBM3 頻寬:AI 模型的瓶頸往往不在運算,而在數據吞吐。H100 的 HBM3 提供了近 3TB/s 的頻寬,確保模型權重能以極速載入。
- 啟用 Transformer Engine (FP8):如果您的推論框架(如 TensorRT-LLM)支持,請啟用 FP8 推論。H100 的硬體 Transformer Engine 能在不損失精度的情況下,將 Llama 3 70B 的推論速度提升數倍。
- 優化高併發 (Context Swapping):對於企業多用戶訪問,H100 支持強大的 Context Swapping 技術,讓模型能以極低延遲切換不同用戶的對話上下文,這對於 RAG 系統非常關鍵。
- 細粒度權限控制:RAG 知識庫必須整合公司現有的 IAM(身分與存取管理)系統。確保 AI 在檢索時,只能訪問該用戶有權查看的文件(例如普通員工無法檢索到高層財務報告)。
結語:企業智慧的新起點
恭喜您。按照上述步驟,您已經在本地強大的 H100 伺服器上,成功搭建了一個安全、受控、懂您業務的真·企業大腦。
這只是開始。有了這個 RAG 基礎,您可以進一步探索 Agentic Workflow(代理工作流),讓 AI 不僅能回答問題,還能根據檢索到的資訊,自動去執行採購、生成報告或發送郵件等任務。
硬體已經就緒,智慧正在成長。請問您的團隊在搭建 RAG 系統時,目前遇到最大的挑戰是數據清理還是軟體選型?
發佈留言